Clarity in Chaos
Designing an AI‑assisted Incident Recovery experience (Phase 1 → Phase 2)
How I helped transform incident recovery from “tool-hopping and tribal knowledge” into a single, role-based workflow—first by shipping a consolidated observability concept as an Individual Contributor, then by leading a cross-org vision as a Design Manager to make recovery faster and more trustworthy.
Imagine it’s payday and the “Pay Employees” flow slows down. Support channels light up. Engineers jump between Slack, dashboards, logs, and runbooks, while leaders ask: “What’s the customer impact?” and the incident commander keeps re-explaining context to every late joiner.
Problem
Incident response was slowed by fragmented tools, missing shared context, and inconsistent “source of truth.”

Technical responder / on-call engineer
"There just seems to be a lot of tools like these that are just all over the place... it's kind of hard to be able to nail down, like, I should check that. Check here or check there".

Incident Commander (IOC)
"We spend valuable time repeating the incident summary and context for every new person who joins the call, manually page teams and often finding the correct owner is time taking process.".

Accountable leader
"What is the real customer impact?". The available technical metrics are too granular and disconnected from business outcomes.".
The Opportunity- What if joining an incident felt less like detective work—and more like stepping into a cockpit where the right information finds you?
The process
Phase 1
Step 1: Make the invisible visible (discovery → shared problem clarity)
Across research + stakeholder conversations, we heard a consistent story: “Tool sprawl” during high-stress incidents, No clear starting point, Logs and deep investigation required tribal knowledge. This became the core framing.
How might we help responders find the top insights without context switching—so recovery speeds up?
Step 2: Resolve structural conflict with a design sprint
What I did: I ran a design sprint with senior stakeholders to: define the value proposition of each surface (what it’s best at), decide what should be the source of truth and remove duplication so users don’t waste time reconciling mismatched information.
Outcome: We landed on a clear flow of information and shipped the first consolidated incident recovery experience.
Step 3: Ruthless simplification through usability learning
1. Identify the health parameters people look for first (what matters in the first 5 minutes),
2. Remove ideas that felt useful but didn’t hold up under pressure (example: a dense timeline at the top that became too hard to scan during real incidents).
How might we help responders find the top insights without context switching—so recovery speeds up?
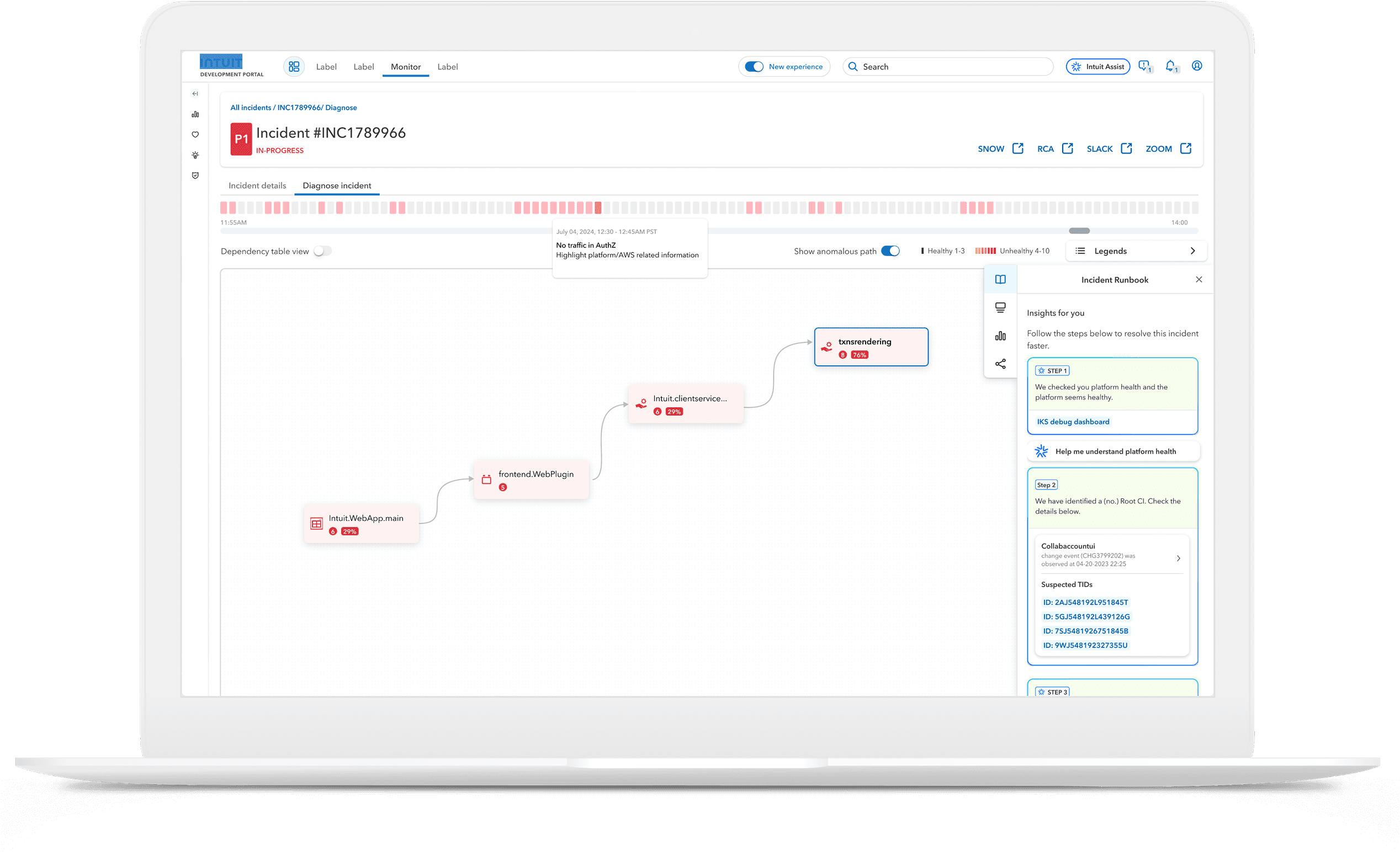
Incident recovery at the end of phase 1
Phase 2
Step 4: Scale from “a better page” to “a better operating model”
A strategic shift:
From “DevPortal as a directory” to DevPortal as Mission Control—a unifying layer on top of existing tools.
We focused on three principles (in human terms):
Clarity in chaos → role-specific views and immediate context
Smart guidance, seamless action → suggestions and guided workflows without removing human control
Unified experience across roles → consistent shared truth, tailored depth by persona
Step 5: Earn trust in AI (the key Phase 2 insight)
The biggest misalignment in Phase 2 wasn’t “should we consolidate?”—it was:
How much should users trust the agent?
Where must humans intervene?
How do we show what the agent checked so users can validate it?
Workshops clarified the answer:
Users need to test hypotheses manually sometimes
The system must show agent reasoning (what signals were checked, what changed, why the conclusion)
A visible confidence score reduces blind trust and supports calibrated decision-making
This shaped Phase 2’s interaction model (role-based canvas, explainability, confidence, and human override).

Incident recovery vision, Phase 2, Watch vision video here
What I shipped + what It led to
Phase 1 (IC): Consolidated incident-centric observability
Aligned leaders across multiple engineering/PM teams on where incident information should live (and what should not duplicate across entry points) via a design sprint.
Shipped the first incident recovery experience that reduced cognitive load and clarified “what to check next.”
From MTTR Target (Recovery time): 76 min → 21 min → We reduced it to 76 min → 47min (≈ 29 min faster, ~38% reduction)
Phase 2 (Design Manager): A trustworthy, AI-assisted recovery future
Led strategy + alignment across roles (PM/Eng/Design/Leaders) to define a role-based recovery canvas + agent assist.
Resolved the core conflict: trust + transparency (what the agent suggests vs. what users must verify) by introducing concepts like agent reasoning visibility and confidence scoring.
Baseline MTTR (reported): 47 min → 33 min (Target is ≈ 14 min faster, ~30% reduction)
Agent quality bar (Phase 2): Early rollout: ~60% accuracy for mid/low severity incidents (Target achieved); 85% accuracy needed to expand to high-stakes incidents (in progress).
Glimpse of the incident recovery journey
Bringing stakeholders together